
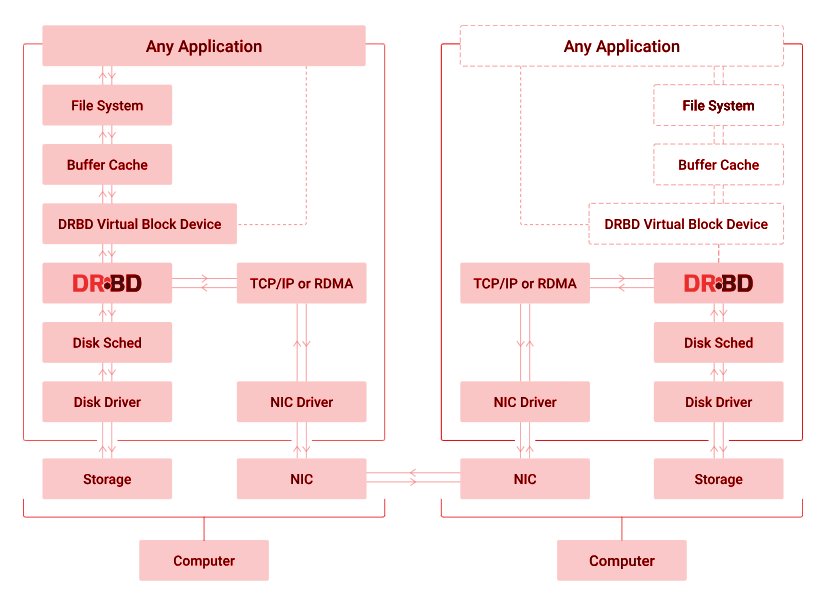
Le but de ce Post est de montrer l’utilisation de DRBD (Data Replication Block Device) qui n’est rien d’autre que l’implémentation sur Linux des protocoles de réplication de bloc de disque des baies de disques les plus performantes du marché.
Pour un exemple pratique, nous allons l’utiliser dans la cadre d’un cluster LAMP (Linux Apache/MySQL/PHP) pour créer ainsi une solution clustérisée en HA de MySQL basée sur deux hôtes Linux distincts distincts.
Préambule
Notre POC se base donc sur deux serveurs distincts de type UBuntu 24.04, mais cela fonctionne globalement à peut près de la même manière (aux commandes systèmes près) sur quasiment toutes les distributions Linux.
Le principe va est de définir dans un premier temps un disque répliqué entre deux serveurs SERVEUR1 et SERVEUR2 grâce à DRBD, puis, une fois ceci en place, y délocaliser une base de données mySQL et un site web PHP sous Apache pour au final faire gérer le HA (gestion des IP, des services, de la santé des serveurs) entre les deux serveurs par le programme KeepAlived qui va gerer le démarrage montage automatique des services sur le bon serveur en bon été de fonctionnement.
Le principe étant de pouvoir « perdre » un serveur sur deux sans que les utilisateurs ne s’en aperçoivent (ou presque).
Les deux hôtes physiques sont dans notre POC les suivants :
SERVEUR1 : 192.168.1.1/24(serveur PRIMAIRE)SERVEUR2 : 192.168.1.2/24(serveur SECONDAIRE)
Nous partons du principe que nous allons, d’un serveur à l’autre et inversement, pouvoir répliquer les données sur une partition « /dev/sdb1 » . Il faudra donc que celle-ci existe sur les deux serveurs avec la même topologie de disque.
DRBD
Préambule
Il y a plusieurs façons de configurer DRBD (synchrone ou asynchrone, actif / actif ou actif / passif, etc), dans notre POC, nous allons nous limiter à la gestion Synchrone de la réplication et de la gestion actif / passif du HA. Autrement dit selon ces deux critères:
- On veut être certain que un bloc écrit sur le serveur primaire sera toujours présent sur le serveur secondaire : c’est de la réplication SYNCHRONE de blocs.
- Un seul serveur est utilisé à un instant « t ». On bascule du serveur 1 vers le serveur 2 si et seulement si le serveur 1 ne répond plus correctement. C’est une gestion du HA en Actif / Passif.
Configuration
Tout d’abord, modifier les fichiers hosts tel que :
root@SERVEUR1: ~# echo "192.168.1.1 SERVEUR1" >> /etc/hosts root@SERVEUR1: ~# echo "192.168.1.2 SERVEUR2" >> /etc/hosts
root@SERVEUR2: ~# echo "192.168.1.1 SERVEUR1" >> /etc/hosts root@SERVEUR2: ~# echo "192.168.1.2 SERVEUR2" >> /etc/hosts
Installer ensuite les binaires de DRBD sur les deux serveurs si c’e n’est pas déjà fait tel que:
root@SERVEUR1: ~# apt install -y "drbd-utils"
root@SERVEUR2: ~# apt install -y "drbd-utils"
Puis, renseigner le fichier de configuration de DRBD « /etc/drbd.conf » sur les deux serveurs tel que :
include "drbd.d/global_common.conf";
include "drbd.d/*.res";
#global { usage-count no; }
#common { syncer { rate 100M; } }
resource r0 {
protocol C;
startup {
wfc-timeout 15;
degr-wfc-timeout 60;
}
net {
cram-hmac-alg sha1;
shared-secret "monPasswordSecreteEntreLesDeuxServeurs";
}
on SERVEUR1 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.1.1:7788;
meta-disk internal;
}
on SERVEUR2 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.1.2:7788;
meta-disk internal;
}
}
Dans cet exemple :
- « protocol » : C’est le type de réplication entre le primaire et le secondaire. C signifie « SYNCHRONE » (A signifiant « ASYNCHRONE » principalement à utiliser pour des réseaux à forte latence et B « SEMI-SYNCHRONE » pour des usages très particuliers)
- Une « ressource » DRBD est grossièrement un périphérique à répliquer et l’ensemble des règles le régissant et le définissant. « r0 » est ici l’unique ressource sur notre serveur, effectivement, vous pourriez avoir plusieurs disques à répliquer et autant de ressources à définir.
- « device » représente le nom du périphérique virtuel créé par DRBD pour gérer notre ressource, il se nomme par défaut «
/dev/drdb0» mais vous pouvez lui donner le nom de votre choix. « disk » est le nom de la partition réelle vers lequel le périphérique virtuel de DRBD doit pointer.
Voilà, la configuration de base est éffecuée, nous pouvons, sur les deux serveurs, démarer le démon DRBD:
root@SERVEUR1:~# systemctl start drbd.service && systemctl enable drbd.service
root@SERVEUR2:~# systemctl start drbd.service && systemctl enable drbd.service
Nous allons maintenant créer les méta données de DRBD, sur les deux serveurs, tel que :
root@SERVEUR1:~# drbdadm create-md r0 initializing activity log initializing bitmap (1600 KB) to all zero Writing meta data... New drbd meta data block successfully created.
root@SERVEUR2:~# drbdadm create-md r0 initializing activity log initializing bitmap (1600 KB) to all zero Writing meta data... New drbd meta data block successfully created.
Nous allons ensuite initialiser le disque DEPUIS LE SERVEUR PRIMAIRE tel que :
root@SERVEUR1:~# drbdadm -- --overwrite-data-of-peer primary all
Il faudra, selon la taille de votre partition à synchroniser, attendre plus ou moins de temps jusqu’à ce que la réplication initialise tous les blocs sur le serveur primaire et sur le serveur secondaire.
Vous pouvez, à tout instant, sur le primaire comme sur le secondaire, voir l’état de la réplication comme indiqué dans l’Annexe « Etat de la réplication »)
Pour terminer, indiquons au serveur SERVEUR2 qu’il va jouer le rôle de SERVEUR SECONDAIRE tel que:
root@SERVEUR2:~# drbdadm secondary all
Une fois cette réplication achevée, toujours depuis le SERVEUR PRIMAIRE, nous allons pouvoir formater la partition avec le système de fichiers de notre choix et la monter sur un répertoire. Nous choisissons « ext4 » comme filesystem et le point de montage sera dans « /data » tel que :
root@SERVEUR1:~# mkfs.ext4 /dev/drbd0 mke2fs 1.47.0 (5-Feb-2023) Creating filesystem with 13106535 4k blocks and 3276800 inodes Filesystem UUID: e892fb0f-8440-4611-9540-0004967d2168 Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624, 11239424 Allocating group tables: done Writing inode tables: done Creating journal (65536 blocks): done Writing superblocks and filesystem accounting information: done root@SERVEUR1:~# mount /dev/sdbr0 /data
Note: Il ne faut pas ajouter ce point de montage dans la fstab, car au boot des deux serveurs, on ne sait pas encore quel sera le PRIMAIRE et quel sera le SECONDAIRE, on va laisser le processus de HA le faire à notre place (voir dans paragraphe « KeepAlived ».
MySQL / Apache / PHP
L’intérêt de ce POST n’est pas de montrer une nième installation de MySQL/Apache/PHP, mais c’est l’exemple que nous utilisons ici pour notre cluster DRBD.
L’essentiel est que tout soit installé dans la partition « /data » de notre disque synchronisé par DRBD, je vous propose l’architecture suivante:
- /data/http : Installation des scripts PHP pour votre Virtualhost Apache
- /data/mysql : Répertoire de data de MySQL contenant votre base de données
- /data/divers : Documentation de votre choix que vous souhaitez retrouver en cas de crash, dumps de DB, dumps des scripts, etc.
La seule « difficulté » (si on peut dire) est de déplacer le datadir de MySQL de /var/lib/ à /data/, pour cela vous devez modifier le fichier de configuration de « AppArmor » pour autoriser MySQL à écrire dans /data/, il faut pour cela ajouter ceci au fichier « /etc/apparmor.d/tunables/alias » tel que :
... alias /var/lib/mysql/ -> /data/mysql/, ...
Puis relancer AppArmor :
root@SERVEUR1 ~# systemctl restart apparmor.service
root@SERVEUR2 ~# systemctl restart apparmor.service
Ensuite, il suffit de dire dans la configuration du démon MySQL que l’on souhaite déplacer les données dans /data/ dans le fichier « /etc/mysql/mysql.conf.d/mysqld.cnf » tel que :
... datadir=/data/mysql ...
Puis déplacer les données et enfin relancer MySQL tel que :
root@SERVEUR1 ~# systemctl stop mysql root@SERVEUR1 ~# mv /var/lib/mysql/* /data/mysqL/ && chown -R mysql:mysql /data/mysqL/ root@SERVEUR1 ~# systemctl start mysql
root@SERVEUR2 ~# mv /var/lib/mysql/* /data/mysqL/ && chown -R mysql:mysql /data/mysqL/
NB) Evidement on ne démarre pas encore MySQL sur le serveur secondaire dont la partition /data est montée sur le primaire.
KeepAlived
Préambule
KeepAlived est un outil qui permet de gérer la Haute Disponibilité des services (Hight Availiability / HA), de surveiller la « santé » de serveurs et de leur ressources et d’automatiser l’arrêt et/ou le démarrage de services en fonction des évènements survenus.
KeepAlived est basé sur la gestion d’un « routeur virtuel » détenant une adresse « IP virtuelle » (VIP / IPV) : KeepAlived va ajouter l’IPV dynamiquement sur le serveur Primaire (Maitre), puis, en fonction de l’état de santé des serveurs, va potentiellement l’enlever du Master pour la donner au Slave (le Secondaire). Le client lui, ne se connectant que sur l’adresse IPV, ne sait pas à priori sur quelle hôte il travaille (SERVEUR1 ou SERVEUR2) d’un point de vue réseau.
Il existe d’autres outils capable de remplir le même rôle tel que Heartbeat, Corosync / Pacemaker, etc.
Notre cas est simple : Gérer la bascule de la gestion d’un disque synchronisé par DRBD d’un serveur Primaire actif à un serveur Secondaire passif et de démarrer les services associés de bases de données (MySQL) et web (Apache).
Installation et configuration
Si ce n’est pas le cas, installer KeepAlived sur les deux serveurs tel que :
root@SERVEUR1:~# apt install -y "keepalived"
root@SERVEUR2:~# apt install -y "keepalived"
Puis éditer, sur chaque serveur, le fichier « /etc/keepalied/keepalived.conf » et y positionner la configuration suivante sur le PRIMAIRE (aka « Master » selon la terminologie Keepalived) :
global_defs {
notification_email { admin@mondomaine.fr }
notification_email_from cluster-drbd-lamp@mondomaine.fr
smtp_server mail.domaine.fr
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 {
state MASTER
interface ens160
virtual_router_id 111
priority 200
advert_int 1
authentication {
auth_type PASS
auth_pass monPasswordKeepAliedDRBDLAMP
}
notify_master /etc/keepalived/notify_master.sh
notify_backup /etc/keepalived/notify_backup.sh
notify_stop /etc/keepalived/notify_stop.sh
virtual_ipaddress {
192.168.1.3/24
}
}
Remarques:
- « state« : Positionner « MASTER » sur le primaire et « BACKUP » sur le secondaire
- « interface » : C’est le nom de l’interface ethernet via laquelle les serveurs vont surveiller leur bonne santé, ici « ens160 »
- « virtual_ipaddress » : L’IP Virtuelle du cluster KeepAlive (ici nous avons choisi 192.168.1.3)
- « notify_master » : Script a déclencher lorsque le noeud devient MASTER selon KeepAlived
- « notify_backup » : Script a déclencher lorsque le noeud devient SLAVE selon KeepAlived
- « notify_stop » : Script a déclencher lorsque le noeud est stoppé selon KeepAlived
Les scripts des « notify » peuvent être plus ou moins complexes selon les clusters à gérer, dans notre cas, ils sont simples et servent à monter la partition DRBD puis à démarrer les services qui vont exploiter les données sur ces partitions.
Keepalived quand à lui se chargera de placer la VIP sur le bon serveur.
Editer, sur le SERVEUR2, le fichier « /etc/keepalied/keepalived.conf » et y positionner la configuration suivante sur le SECONDAIRE (aka « Backup » selon la terminologie Keepalived) :
global_defs {
notification_email { admin@mondomaine.fr }
notification_email_from cluster-drbd-lamp@mondomaine.fr
smtp_server mail.domaine.fr
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 {
state BACKUP
interface ens160
virtual_router_id 111
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass monPasswordKeepAliedDRBDLAMP
}
notify_master /etc/keepalived/notify_master.sh
notify_backup /etc/keepalived/notify_backup.sh
notify_stop /etc/keepalived/notify_stop.sh
virtual_ipaddress {
192.168.1.3/24
}
}
Scripts de Notify KeepAlived (à placer sur les deux serveurs) :
1 – « /etc/keepalived/notify_master.sh » :
#!/bin/bash systemctlstopapache2 systemctlstopmysql drbdadm primary r0 mount /dev/drbd0 /data systemctl start mysql systemctl start apache2
2 – « /etc/keepalived/notify_backup.sh » :
#!/bin/bash systemctl stop apache2 systemctl stop mysql umount /data drbdadm secondary r0
3 – « /etc/keepalived/notify_stop.sh » :
#!/bin/bash systemctl stop apache2 systemctl stop mysql umount /data drbdadm secondary r0
KeepAlived va utiliser le protocole VRRP sur son réseau avec l’ID de routeur « virtual_router_id » et sa clé secrete « auth_pass » : Vérifiez qu’aucun autre routeur (ou démon KeepAlived) n’écoute avec VRRP sur le même LAN avec les mêmes identifiants sous peine de catastrophe …
Enfin il faut démarrer KeepAlived sur SERVEUR1 et sur SERVEUR2 et les mettre en démarrage automatique : Ce sont les seuls services à positionner en automatique car c’est eux qui ont en charge de stopper / démarrer les autres services en fonction de l’état de santé des serveurs :
root@SERVEUR1:/# systemctl start keepalived root@SERVEUR1:/# systemctl enable keepalived Synchronizing state of keepalived.service with SysV service script with /usr/lib/systemd/systemd-sysv-install. Executing: /usr/lib/systemd/systemd-sysv-install enable keepalived
Test de bascule
Avant de continuer, il est indispensable de vérifier que Keepalive joue bien son rôle et fonctionne bien, car l’étape suivante est la mise en place des scripts de , le problème ne sera plus d’ordre système mais d’ordre développement.
Pour se faire, le mieux est de simuler un « crash » afin de vérifier si le FailOver (bascule vers le secondaire) e fait dans les règles de l’art et enfin si le retour vers le primaire se fait correctement. Le mieux, afin d’éviter un power off brutal d’un serveur, et de déconnecter le serveur du réseau et de vérifier que l’IPV bascule bien, que la partition répliquer par DRBD est bien récupérée, et les services démarrés :
- SERVEUR2 AVANT BASCULE :
root@SERVEUR2:/data# df -hP | grep drbd0
root@SERVEUR2:~# ip a | grep ens160
inet 192.168.1.2/24 brd 192.168.212.255 scope global ens160
root@SERVEUR2:~# netstat -len | grep :80
root@SERVEUR2:~# netstat -len | grep :3306
- SERVEUR2 APRES BASCULE :
root@SERVEUR2:/data# df -hP | grep drbd0
/dev/drbd0 49G 36K 47G 1% /data
root@SERVEUR2:~# ip a | grep ens160
inet 192.168.1.2/24 brd 192.168.212.255 scope global ens160
inet 192.168.1.3/24 scope global secondary ens160
root@SERVEUR2:~# netstat -len | grep :80
tcp6 0 0 :::80 :::* LISTEN 0 438316
root@SERVEUR2:~# netstat -len | grep :3306
tcp 0 0 127.0.0.1:33060 0.0.0.0:* LISTEN 117 437520
On constate bien que l’IPV « 192.168.1.3 » a été affectée à SERVEUR2, que la partition /dev/drbd0 a bien été montée sur /data et que les services MySQL (écoute sur le port 3306) et Apache ( écoute sur le port 80) ont bien été lancés : Tout est Ok.
Annexes
DRBD : Statut des noeuds
Sur le serveur primaire comme sur le secondaire, à tout moment on peut connaitre le statut de DRBD (type de serveur et état du disque) tel que :
root@SERVEUR1:~# drbdadm -v status drbdsetup-84 status r0 r0 role:Primary disk:UpToDate
DRBD : Etat de la réplication
Sur le serveur primaire comme sur le secondaire, à tout moment on peut connaitre l’état des disques et de la synchronisation tel que :
root@SERVEUR2:~# cat /proc/drbd version: 8.4.11 (api:1/proto:86-101) srcversion: 211FB288A383ED945B83420 0: cs:SyncTarget ro:Secondary/Primary ds:Inconsistent/UpToDate C r----- ns:0 nr:17964556 dw:18226800 dr:0 al:8 bm:0 lo:1 pe:4 ua:0 ap:0 ep:1 wo:f oos:34203828 [=====>..............] sync'ed: 34.8% (33400/51196)M finish: 0:13:54 speed: 40,972 (35,800) want: 41,000 K/sec
DRBD : Inversion du sens de réplication
Vous pouvez à tout instant inverser le sens de la réplication, cela consiste tout simplement à stopper la réplication, à définir le primaire en secondaire, le secondaire en primaire, et à relancer à réplication tel que:
root@SERVEUR1:~# systemctl stop apache2 && systemctl stop mysql root@SERVEUR1:~# umount /data root@SERVEUR1:~# drbdadm secondary r0
root@SERVEUR2:~# drbdadm primary r0 root@SERVEUR2:~# mount /dev/drbd0 /data root@SERVEUR2:~# systemctl start mysql && systemctl start apache2
NB) Ceci est équivalent à stopper Keepalived sur le serveur SERVEUR1.
Attention, ceci se fait services stoppés car il faut le faire partitions démontées d’un point de vue système.